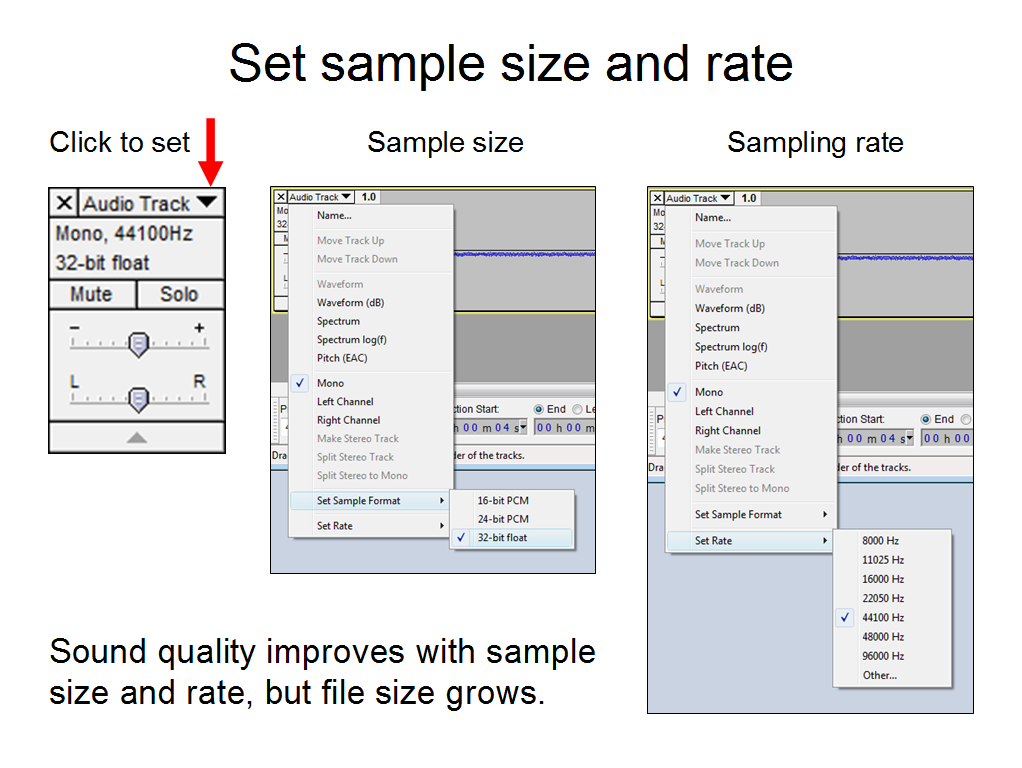
As with other forms of data, we capture as much information as we can initially, do our editing, then compress for distribution as the last step. With images, that means setting our cameras to capture as many pixels as we have room for. With audio, we raise quality by increasing sample size and the rate of sampling:
Like image or video compression, audio compression is lossy. Information is lost during the compression process, and it can not be recovered with de-compression. Engineers working on compression algorithms pay attention to the limitations of the human ear, and attempt to retain all sound that can be heard.
The MP3 audio compression algorithm is widely used for music and speech, and has made the distribution of music and podcasts on the Internet economically feasible. When you compress an MP3 file, you are able to specify the number of bits it will require per second. (There are also variable bit rate MP3 encoders, but they are not as widely supported for playback in MP3 players).
As with any lossy compression technique, there is a tradeoff between quality and file size. This is illustrated in the following examples, in which one recording was compressed by three different amounts.
The original 7.86 second recording was made at 96,000 24-bit samples per second. Uncompressed at that data rate it would have been over 130 megabytes. The program that recorded it saved it in a .wav file using a codec (coder-decoder) that compressed it. That .wav file is 676 kilobytes. I further compressed it three times, producing three smaller .mp3 files.
| Audio file |
File size (Kbytes) |
Bit rate (Kbits/s) |
| Play original (alexander.wav) | 676 | 688 |
| Play low quality (alexanderlowQ.mp3) | 16 | 16 |
| Play medium quality (alexandermedQ.mp3) | 124 | 128 |
| Play high quality (alexanderhighQ.mp3) | 309 | 320 |
The examples in this note were created using audacity, an open source audio processing program.